Semantic Database Design largely off the shelf
I wrote parts of this story a few times, this is the last time I write about it. Maybe I am going to build this semantic database, which is not that hard, as you will read below.
A semantic database is not hard to do. Most parts are off the shelf available, or the knowledge how to build them is available.
A good example of a semantic database is OpenEhr. OpenEhr was designed years before this idea. Somewhere around the year 2000. The idea is designed by Thomas Beale, but without giving account about how big it can be. I discussed it a few times but no one wanted to go this way, let me explain.
I am developing software for this design since almost 12 years. I created commercial implementations, a few times, in Java, in Java-Spring, in Golang. So I am very familiar with the ideas. From the beginning, I had the feeling that it could be bigger than it is. I already did make it bigger by implementing more Reference-models in one implementation, but that was not in a flexible way, it was hardcoded, in fact, quite the opposite of OpenEhr-thinking. But I learned and the software-landscape changed a lot last ten years, that helped too.
Reference-model, and you probably want to know what this is and what it does. In the past it was difficult to explain, because it was so far from the regular application thinking. But now many developers are familiar with the concepts which were hardly available 10 years ago. I am thinking about micro-services, kubernetes, cloud, document-databases, JSON.
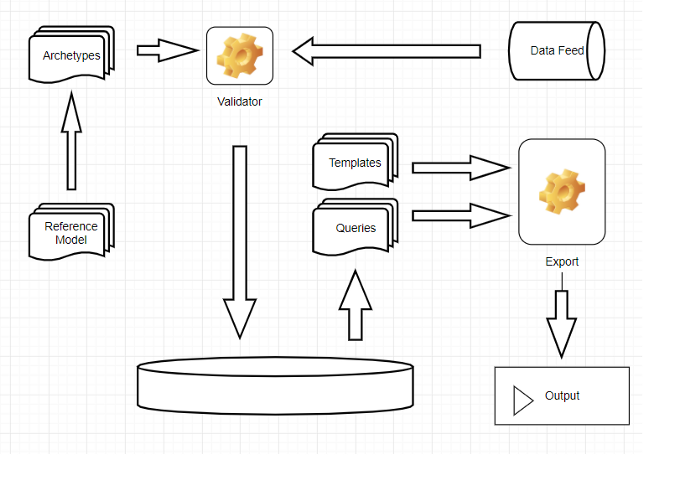
Nothing explains better than a drawing. I made one with an online drawing tool. It is simple, and so is the system. I will explain the parts of the system of which the Reference-model is an important part, a good starting point.
But also, why? What are the advantages? Such a simple idea that can change so much. Why is that?
The advantages of the Semantic Database-concept
- Modeling of data can be done by domain-experts which can be non-technical-educated persons. For example, modeling of a healthcare application can be done by physicians, modeling for the agricultural sector can be done by agricultural specialists. Imagine the situation that this is being done by programmers without specialized knowledge of the domain where the software is going to be used.
- Flexibility, models can be updated, queried and coexist in the same database as the previous are stored and queried. No new tables need to be created. The database is always able to represent the newest visions in the domain while maintaining the older visions for history/research-purpose.
- The semantic power, all data are explained, no dark relationships, no cryptic table names, everything is defined, explained, and in context of the recording.
The Reference-model
The reference-model is an overview model which can be specialized or constrainted in archetypes. The classes in the reference-model are few and their structure is very open. The reference-model is a semantic base, it already has the names which will return in the archetypes.
For example, in OpenEhr, which has a clinical Reference-model, there are a few main-classes, which can represent almost any possible medical data-item or process. These are Observation, Evaluation, Action, Instruction and a few more. A patient comes to the doctor, and has a complaint, the doctor checks the patient, Observations, he thinks about it, Evaluation, and he describes something, etc.
That is not all. Besides the clinical part in OpenEhr, there are common parts which can be used in conjunction with more reference-models. F.e. the demographic reference-model and the datatypes and data-structures. You find these very useful models also on the OpenEhr-website.
Flexibility: It is no problem of having more then one reference model, no problem of having five, or ten, or more versions of the same, simultaneously, in the same database, in the same application. It is also possible to run more applications, simultaneously in the same kernel. The archetypes mention in their metadata on which reference-model/version they operate. And the classes on which archetypes are based are the classes from the reference-model.
The Archetypes
The archetypes are specializations/constraints on the classes from the reference-model. It is easy to explain what it is by an example.
In OpenEhr the most boring example of an archetype is blood-pressure, because it is very useful to explain the mechanism. In an archetype you can define that the systolic must be higher than the diastolic. Also, if in a new version, you want to record the position of the patient while taking the bloodpressure, both versions of the archetype can co-exist. So is an extension on a dataset in use without changing any table, and the old data are still available and usable. Also is in the archetype the unit which is measured. There is more to say about this, but that is too much detail.
This may all seem very logical and naturally, but I can tell you horror stories of hospitals or other companies which have 10.000 tables in use, and no-one is able to oversee what their purpose is. These days are over in a semantic database-structure.
You can find many archetypes based on the OpenEhr reference-model on their website. Take a look at it as example and try to rethink the concept in the data-structures you need..
Validation
The archetypes are used to validate incoming datasets against, after that the datasets which can be in JSON, will be stored in the database. So of every data set in the database is sure that it validated well against archetypes. The archetypes themselves are also stored in the database to tell us the story about the data set, the context, who designed it, what it means.
Queries
There is a archetype-path-related query language which can be translated into the MongoDB-query language. It is called AQL (archetype-query-language). You can find a good paper on it: https://www.sciencedirect.com/science/article/pii/S1532046419302588
if it disappears from the internet, there will be copies of it. Google on “archetype query mongodb”
Templates
And the last item is templates. They are in fact, a number of queries. They can be used to build screens and messages. There are examples on the archetype-page I showed before.
Okay, what do we have?
Starting with the reference-model, we need something to express data-models in and generate them. Although there is a lot of discussion, I would go for Acceleo: run it in a jar as micro-service, let it have an API. Shouldn’t be too hard to do. Acceleo has as unique feature that it works with templates so it can generate in many programming languages. C#, Java, Go, Javascript, it should all be possible.
The archetypes, there is a AOM (archetype object model) on the openehr-website. It is largely reference-model agnostic. Use the AOM-implementation as a micro-service or build your own. It is not hard, especially when you have the Acceleo-micro-service running ;-). The implementation OpenEhr uses is in java and called: Archie.
Thomas Beale has designed a language to express archetypes, it is called ADL (archetype-definition language). It is also in Archie, also is the ANTLR for reading ADL. Usable from the shelf. For internal use I would prefer JSON archetypes, much easier to read-write, and use them for validation. But to communicate with the outside world, ADL is nice.
An archetype-editor, maybe that the LinkEhr is reference-model agnostic. Else, that has to be build. LinkEhr can be a good inspiration how it will look like. It has the typical explorer view, left side the tree of archetype-items, and right side, the contents of a tree item.
An archetype-editor can be build in web-version, or local binary version.
The validation is an easy visitor pattern running over the archetype-tree and compare it with the data-tree.
We already talked about the queries, and the screen builder.
That is it, a semantic database is ready to use. No more do you need to search for the meaning of data, no more do you have to guess what a programmer was intending 5 years ago, you remain flexible for ever, and updating applications to a new standard will be easy.
I think an experienced developer can build this in less then 6 months.
One important thing to remember, do not re-invent wheels, use, when appropriate, the standards Thomas Beale designed, not because they are the best solutions, but they are very good, anyway, good enough, and more important, in this way, we keep our efforts compatible and flexible and cheap.

